 2025-03-24
2025-03-24 3 min read
3 min read피그마에서 자원을 Export 후 Font Cleaner로 1차 변경을 하고 Find & Replace Tool에 등록한 Glyphs 자원을 사용해 최종 결과물까지 생성하는 비디오 클립입니다.
전처리기 Font Cleaner
1차 개발에서는 도트 작업 이전에 Batch를 사용해 전처리 작업 후 작업을 했습니다. 다국어 지원에서는 프로그래밍을 통해 더욱 향상된 전처리를 했습니다.
전처리기 Font Clenaer를 사용해 세리프 글꼴을 직교 형태로 다듬고, 디더링 없이 앨리어싱을 합니다. OCR을 사용해 직교 형태로 다듬는 것을 돕습니다.
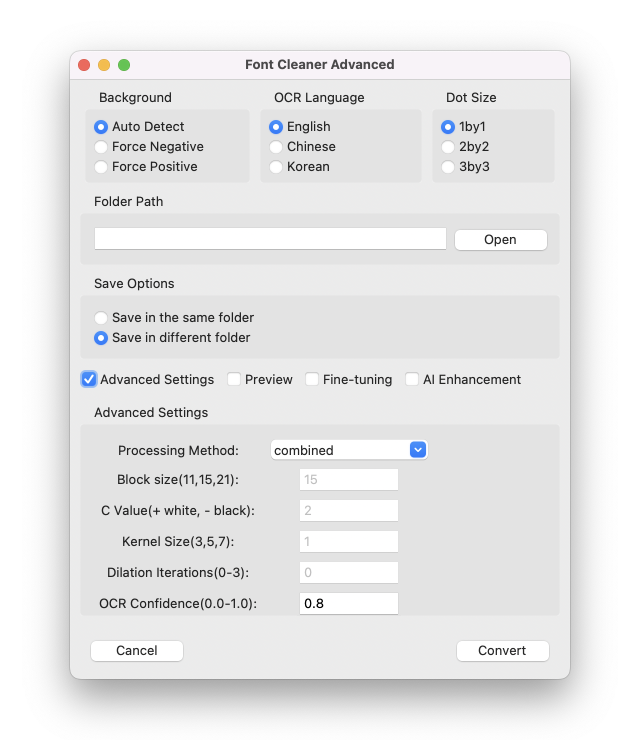 Font Cleaner를 사용해 BMP로 변환 후 도트 작업을 거쳐 고객사에 전달하여 품질 컨펌을 받고 최종 결과물의 기준으로 확정해 최종 산출물의 방향을 수립했습니다.
Font Cleaner를 사용해 BMP로 변환 후 도트 작업을 거쳐 고객사에 전달하여 품질 컨펌을 받고 최종 결과물의 기준으로 확정해 최종 산출물의 방향을 수립했습니다.
Find & Replace Tool
 Font Cleaner를 사용해 품질을 개선할 수 있었으나 상용 제품으로 사용하기에는 조금은 부족했습니다. 영어와 중국어 도트작업은 한글과는 다른 어려움 있었습니다.도트 작업은 그라데이션 없이 하나의 픽셀로 형태를 정의합니다. 작은 글자의 경우 픽셀 하나에 많은 영향을 받게 됩니다.
Font Cleaner를 사용해 품질을 개선할 수 있었으나 상용 제품으로 사용하기에는 조금은 부족했습니다. 영어와 중국어 도트작업은 한글과는 다른 어려움 있었습니다.도트 작업은 그라데이션 없이 하나의 픽셀로 형태를 정의합니다. 작은 글자의 경우 픽셀 하나에 많은 영향을 받게 됩니다.
라틴문자의 경우 대부분 하나의 형태(Shape)으로 되어 있으며 대소문자가 있어 글자 크기가 네모꼴에 비해 작습니다. 이는 형태감을 도드라지게 하며 같은 굵기와 크기를 작업자 간에 유지하는 것은 매우 어렵습니다.
한자는 네모꼴로 되어 있어 직교형태로 단순화하는 점에서는 라틴어보다는 작업에 유리하나 한정된 네모꼴 안에 많이 획이 사용되는 경우가 있습니다. 공간 안에 최대한 같은 굵기와 가독성을 유지하기 위해 실물 크기로 화면을 열람하며 작업합니다.
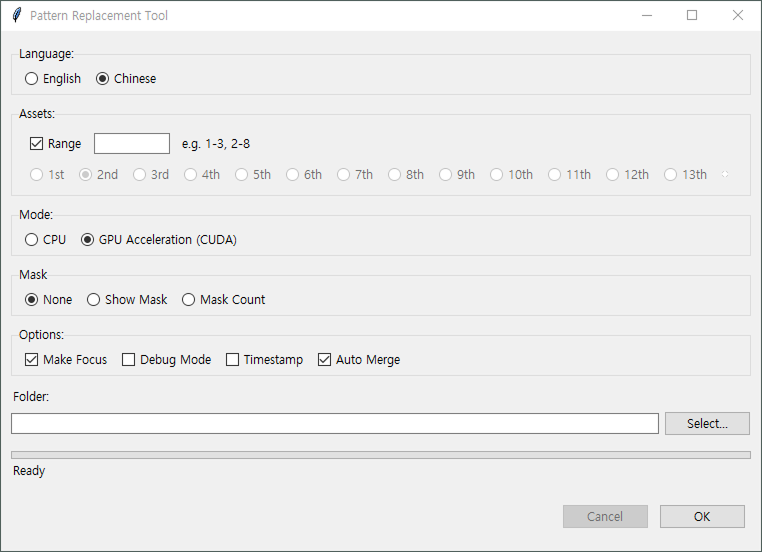
작업의 안정성과 편의성을 위해 Glyphs를 찾고 바꾸는 도구를 개발했습니다. 원본에서 찾을 글자들을 등록하고 도트 작업을 통해 변경할 글자를 등록해 변경하는 도구입니다.
5가지 유형의 글자를 Find & Replace로 등록하면 좋겠지만, Find & Replace로 등록한 자원은 3,207개이며, Find 자원이 3배 이상 많습니다. Find 자원이 많은 이유는 힌팅으로 인해 글자가 픽셀 그리드에 맞춰 변형합니다. 또한 커닝으로 픽셀 정렬이 맞추어져 있지 않은 경우도 있습니다. 따라서 Export 한 글자는 같은 크기라도 픽셀 단위에서는 제각기 달라 10개 이상의 Find가 만들어집니다.
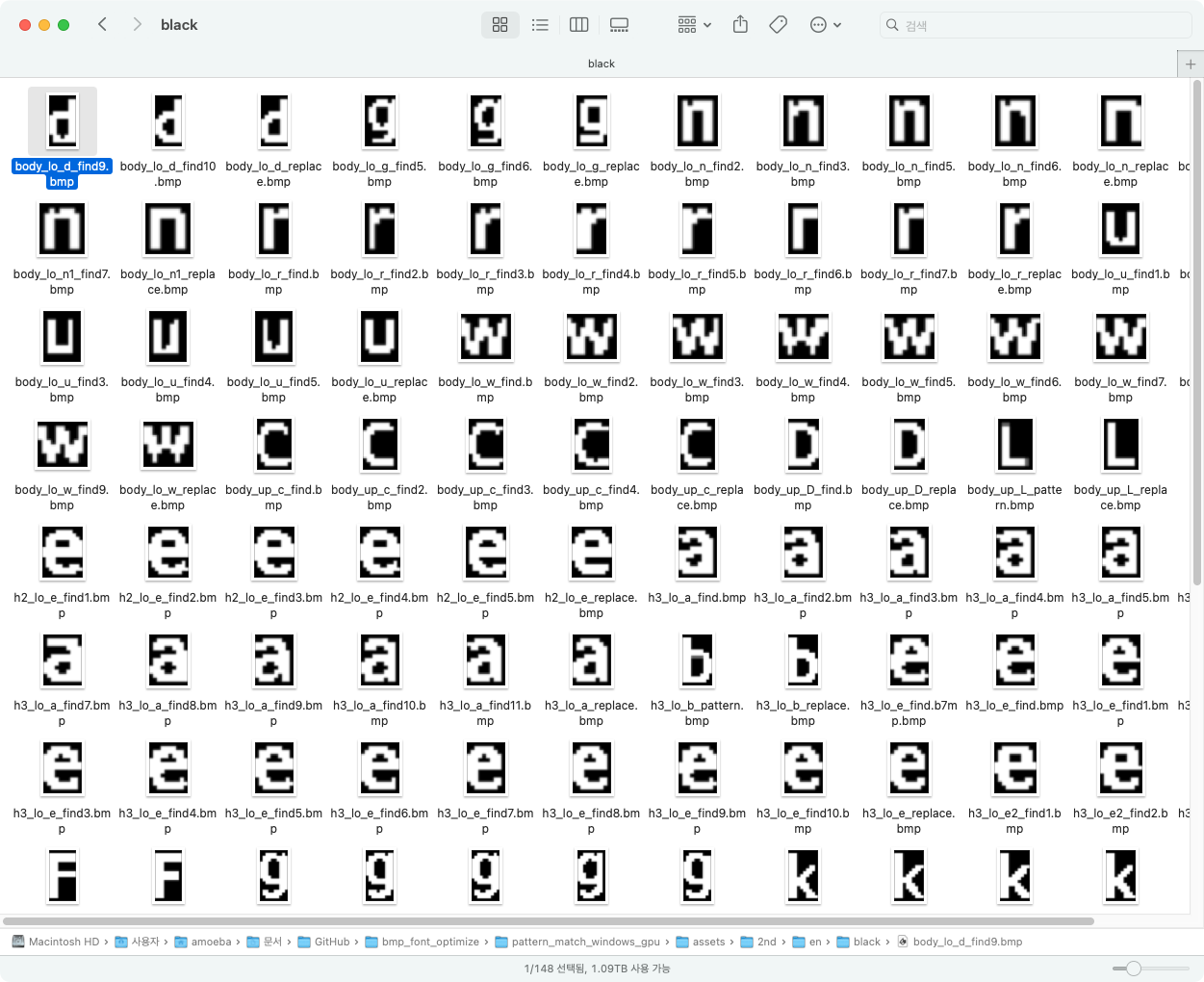
Find & Replace에 사용할 Asstes은 영역 별로 Assets폴더에 등록합니다. Find & Replace 실행 시 Assets 폴더를 순차적으로 완료하며 자원을 업데이트해 완성본을 만듭니다.
마치며
두 개의 작업 도구 외에 도트 작업에 필요한 도구들 전체 자원을 하나의 이미지로 병합하기, 완료한 작업 마킹하기와 같이 다양한 도구를 개발해 사용했습니다. 애플리케이션은 CUDA를 활용한 GPU 가속을 적용했습니다. CPU 기반 멀티 프로세싱에 비해 GPU 병렬 처리로 비교할 수 없이 빠른 속도를 체감할 수 있었습니다.
 개발 과정에서 OCR을 활용하여 폰트를 찾는 방법도 시도했지만, 찾은 후 변경 시 사용할 글꼴 크기를 정확하게 보장하기 어려워 효율성이 떨어진다고 판단하여 적용하지 않았습니다. Find&Replace는 정확하고 빠른 글자 찾기를 만드는 것이 중요했습니다. Canny를 사용한 윤곽 추출 방법 OCR을 이용한 방법 등을 검토했으나, 라틴 문자의 경우 어센더(ascender), 디센더(descender), x-height 등의 개념이 있습니다. 한자와 라틴 문자는 글자를 판독하는 외부 공간의 크기가 일정하지 않습니다. 이를 고려해 OCR 블록의 줄맞춤까지는 했으나, 1~2픽셀로 글자 크기가 정해지는 상황을 고려했을 때 원하는 Replace 대상을 찾는 것에는 어려움이 있었습니다. Replace가 아닌 Retouch 또는 Create으로 접근하기 위해 AI를 개발해 학습 시켰으나 완료하지는 못했습니다.
개발 과정에서 OCR을 활용하여 폰트를 찾는 방법도 시도했지만, 찾은 후 변경 시 사용할 글꼴 크기를 정확하게 보장하기 어려워 효율성이 떨어진다고 판단하여 적용하지 않았습니다. Find&Replace는 정확하고 빠른 글자 찾기를 만드는 것이 중요했습니다. Canny를 사용한 윤곽 추출 방법 OCR을 이용한 방법 등을 검토했으나, 라틴 문자의 경우 어센더(ascender), 디센더(descender), x-height 등의 개념이 있습니다. 한자와 라틴 문자는 글자를 판독하는 외부 공간의 크기가 일정하지 않습니다. 이를 고려해 OCR 블록의 줄맞춤까지는 했으나, 1~2픽셀로 글자 크기가 정해지는 상황을 고려했을 때 원하는 Replace 대상을 찾는 것에는 어려움이 있었습니다. Replace가 아닌 Retouch 또는 Create으로 접근하기 위해 AI를 개발해 학습 시켰으나 완료하지는 못했습니다.
